안녕하세요 크리넥스을라스입니다.
오늘은 스파크의 데이터 프레임을 생성하는 법과 스키마에 대해서 정리해보려고 합니다.
데이터 프레임 생성
먼저 데이터 프레임을 생성하는 방법입니다. 간단하게 현재 EPL 득점 순위 상위 5명에 대한 정보로 만들어 보겠습니다.

먼저 스칼라에서 데이터 프레임을 만들 때는 Sequence 클래스를 사용해 다음과 같이 작성하면 됩니다.
생성하면 컬럼 이름이 없기 때문에 뒤에 toDF() 명령어로 컬럼명을 지정해주시면 컬럼명이 추가됩니다.
# 데이터 프레임 생성(컬럼명 X)
val self_df = spark.createDataFrame(Seq(("엘링 홀란드", 21), ("해리 케인", 15),
("이반 토니", 12), ("미트로비치", 11),
("모레노", 10)))
# 데이터 프레임 생성(컬럼명 O)
val self_df = spark.createDataFrame(Seq(("엘링 홀란드", 21), ("해리 케인", 15),
("이반 토니", 12), ("미트로비치", 11),
("모레노", 10))).toDF("이름", "득점")

파이썬에서는 Sequence 클래스가 아니라 리스트([ ])에 담아주시면 됩니다.
self_df = spark.createDataFrame([("엘링 홀란드", 21), ("해리 케인", 15),
("이반 토니", 12), ("미트로비치", 11),
("모레노", 10)]).toDF("이름", "득점")
또한, RDD를 데이터 프레임으로도 변환할 수 있습니다.
먼저 스칼라입니다.
# RDD 생성
val self_RDD = sc.parallelize(Array("엘링 홀란드", "해리 케인", "이반 토니", "미트로비치", "모레노"))
# 데이터 프레임 변환
val self_RDD_df = self_RDD.toDF()
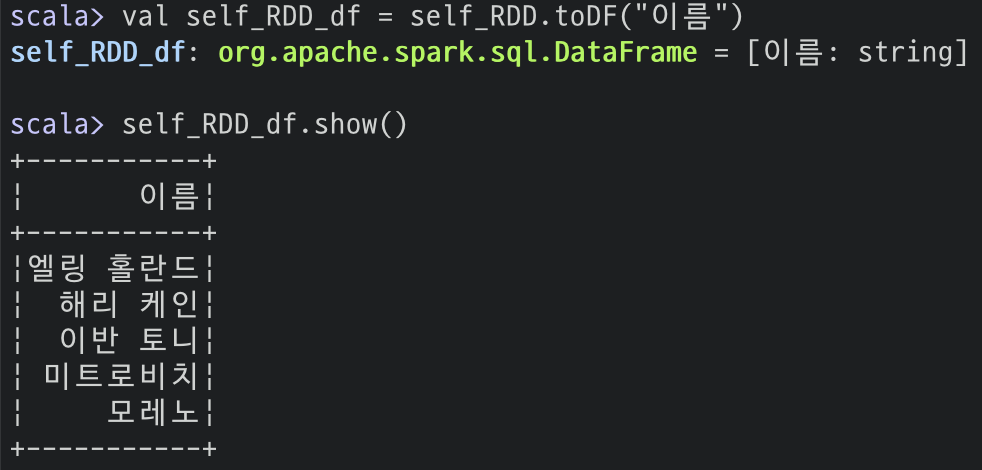
이름과 득점 형태로 만들려면 다음과 같이 하시면 됩니다.
val self_RDD2 = sc.parallelize(Seq(("엘링 홀란드", 21), ("해리 케인", 15),
("이반 토니", 12), ("미트로비치", 11), ("모레노", 10)))
val self_RDD2_df = self_RDD2.toDF()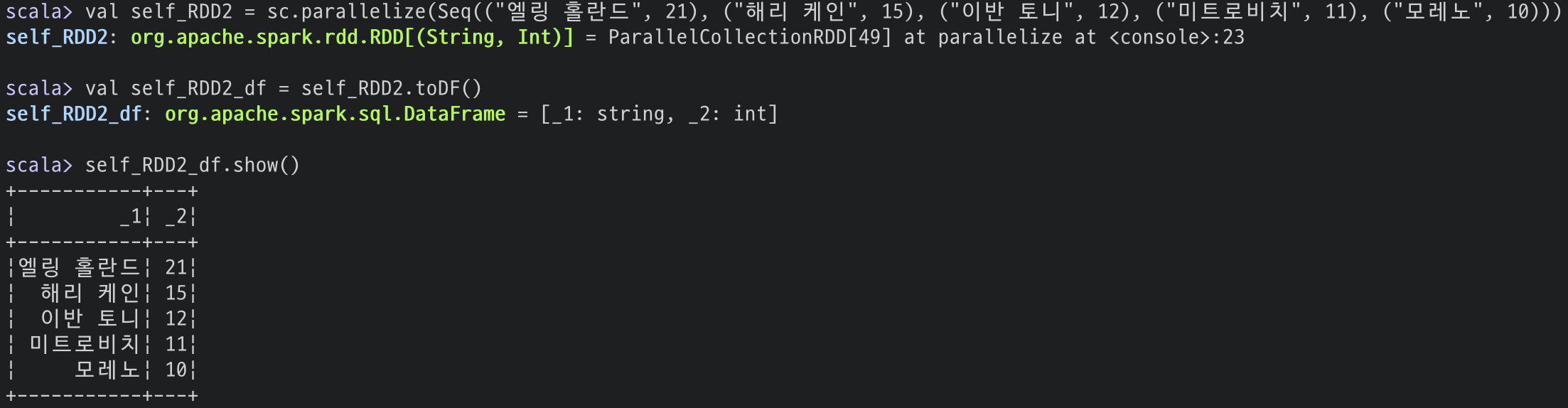
파이썬으로는 판다스의 데이터 프레임을 스파크의 데이터 프레임으로 변환해보도록 하겠습니다.
# 판다스 라이브러리
import pandas as pd
# 판다스 데이터 프레임 생성
data = pd.DataFrame({"경기도": ["김포", "파주", "부천"],
"서울시": ["마곡", "가양", "마포"],
"강원도": ["춘천", "홍천", "화천"]})
# 스파크 데이터 프레임으로 전환
self_data = spark.createDataFrame(data)
스키마(Schema)
스파크에서는 데이터 프레임을 불러오기 전에 스키마를 정의해 지정할 수 있습니다. 데이터나 컬럼 수가 적으면 크게 의미가 없지만, 데이터 크기도 크고 컬럼도 20개 이상이라면 스키마를 미리 정의해 주는 게 좋습니다.
스키마를 정의하는 방법은 두 가지가 있습니다. 하나는 프로그래밍 스타일 방법, 다른 하나는 DDL(Data Definition Language)입니다.
데이터는 EPL 득점 순위를 사용했습니다.
(득점 변동이 조금 있었네요)
첫 번째 방법
# 스칼라
import org.apache.spark.sql.types._
# 스키마 정의
val eplSchema = StructType(Array(StructField("선수", StringType, false),
StructField("팀", StringType, false),
StructField("경기", IntegerType, false),
StructField("득점", IntegerType, false),
StructField("생년월일", DateType, false),
StructField("신체", StringType, false)))
# 데이터 불러오기
val epl = spark.read.format("csv")
.schema(eplSchema)
.option("header", true) # header를 true로 설정해야 컬럼 중복을 피할 수 있음
.load("/Users/inamsu/Desktop/epl.csv")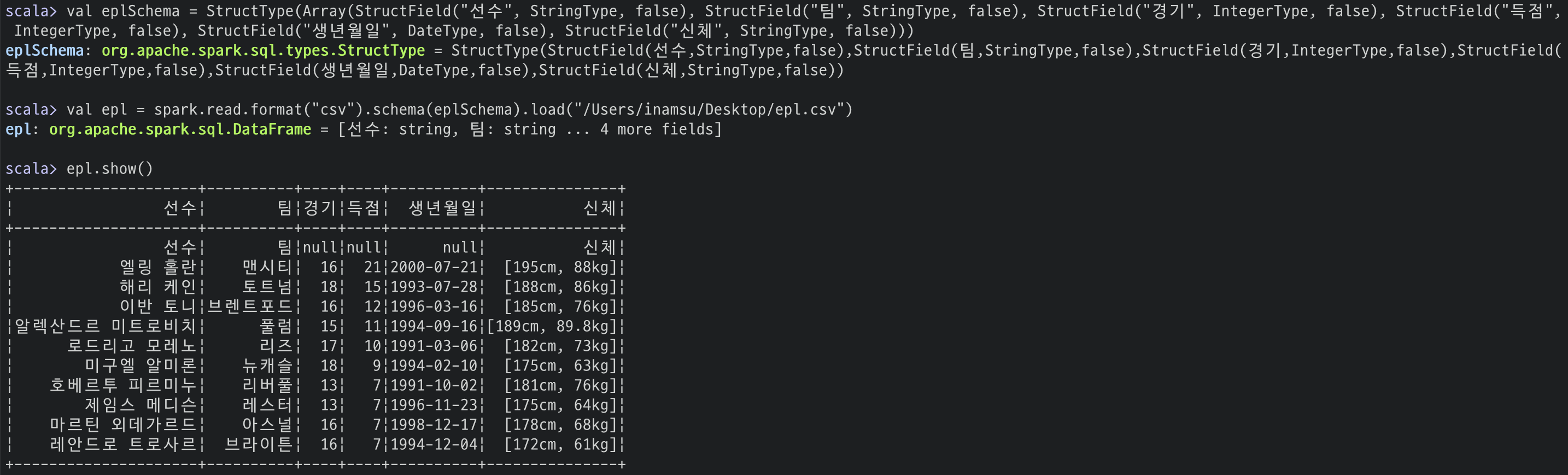

# 파이썬
from pyspark.sql.types import *
# 스키마 정의
eplSchema = StructType([StructField("선수", StringType(), False),
StructField("팀", StringType(), False),
StructField("경기", IntegerType(), False),
StructField("득점", IntegerType(), False),
StructField("생년월일", DateType(), False),
StructField("신체", StringType(), False)])
# 데이터 불러오기
epl = spark.read.format("csv")
.schema(eplSchema)
.option("header", "true)
.load("/Users/inamsu/Desktop/epl.csv")
두 번째 방법
# 스칼라
# 스키마 정의
val eplSchema2 = "name STRING, team STRING, match INT, goal INT, birth DATE, body STRING"
# 데이터 불러오기
val epl = spark.read.format("csv")
.schema(eplSchema2)
.option("header", true)
.load("/Users/inamsu/Desktop/epl.csv")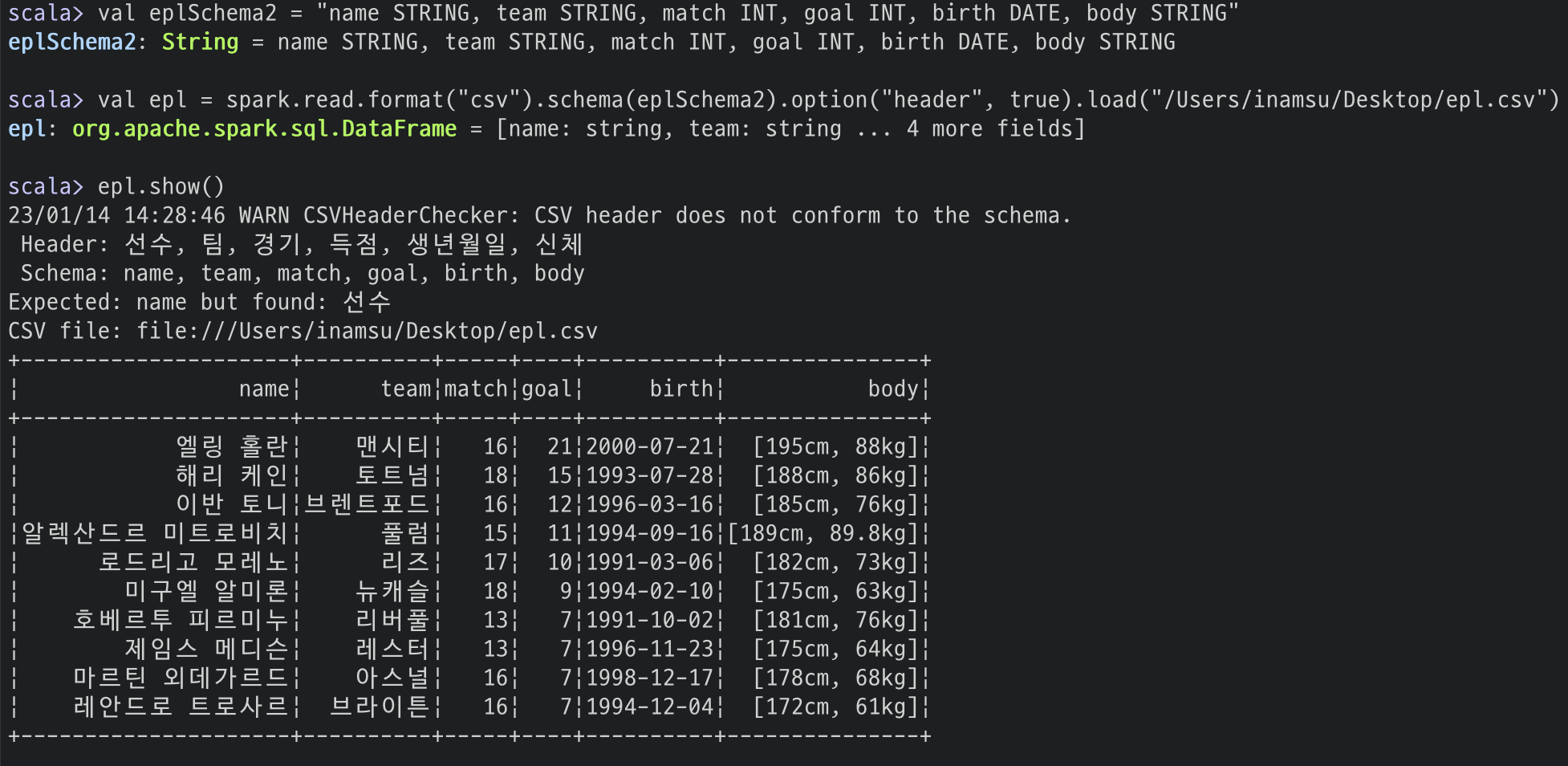
한글로 스키마를 정의한 경우는 Syntax error가 발생해서 저는 영어로 변경했습니다.

# 파이썬
# 스키마 정의
eplSchema2 = "name STRING, team STRING, match INT, goal INT, birth DATE, body STRING"
# 데이터 불러오기
epl = spark.read.format("csv")
.schema(eplSchema2)
.option("header", "true")
.load("/Users/inamsu/Desktop/epl.csv")
첫 번째 방법을 사용할 때 저는 꼭 실수가 발생해서 두 번째 방법이 좀 더 직관적인 것 같습니다.
'스파크(Spark)' 카테고리의 다른 글
| 스파크 경험해보기 (0) | 2023.01.07 |
|---|
